索引篇
在大批量数据查询中,能否利用索引来加快标的数据命中是优化查询效率的关键;
索引检索
索引简述
MongoDB 的索引是采用标记实体数据储存的内存地址映射到实现,查找数据的时候使用索引,相当于利用明细地址去寻找一间餐厅,效率是最好的;
- 优点 - 寻址速度快;
- 缺点 - 索引大小随着数据量和索引字段的值集合增大而变大
索引大小
上述观点已经支持,索引的大小与数据量和索引字段的值有关,当数据量增大,单个索引所储存的索引区域内容就会变大;同理,索引字段包含的(不同)值越多,索引所需要记录的储存地址也会变大;
索引种类
索引的种类有好几种,这里只针对单列索引进行记录和优化;
- 单列索引
- 多列索引
- 多键索引
- 文本索引
- 2d
- 2dsphere
- hash索引
索引对比
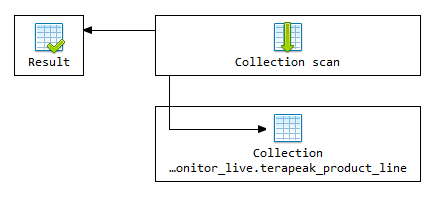
在没有使用索引的情况下,Mongodb的检索策略采用的是Collection scan(集合扫描),这是所有检索方式中最慢的一种,它会遍历当前搜索范围内的所有文档,一条条地去做条件比对;
假设集合数据量为1w条,那么就需要做1w次对比了,查询案例中,耗时2.5s;

我们加入了一个createdat字段作为搜索条件,用于缩小检索范围,但是createdat字段并没有创建索引,可以从检索策略里看到依然采用的是Collection scan,在 1w 条数据的检索案例,依旧耗时约 2.2s(由于被检索过的数据会进入Mongodb的缓存区域,所以比案例1要快一点);

加入了索引字段作为检索条件后,检索的策略变更为Index scan(索引扫描),Mongodb会先去索引找地址,再收集到的地址进行找数据,1w的检索案例也从2.2s降至0.58s;
在复杂的检索过程当中,注意$match条件的字段采用索引字段,则检索效率将会大大提升;
总结
MongoDB索引优化就是把数据检索范围收窄并利用索引更快地定位数据;
分片集群扩展
索引在分片集群中的表现会有一定的折扣,原因在于Mongodb分片集群中,如果检索的索引并非分片索引,事实上Index scan会同时发生在集群的各个机器上;
假设当前集群有3台机器,数据量有1w的分片集群Mongdb,并且分片键不是检索索引键,假设单片执行Index scan需要1s,
- 情况1 - 数据被均匀得分配到3个分片上;
那么3个片会并执行检索时间必定会大于1s,查找的索引信息,需要经过内部汇总到primary上进行合并,这个时候才得出所有数据的地址;
- 情况2 - 数据绝大部分甚至全部集中于某个分片上;
率先能够满额匹配所有数据的分片会告知primary,primary会抛弃其他片的检索动作,直接采用优先分片,这时候执行时间与单片一致,约1s;
- 情况3 - 根本没有数据在分片上
这种情况一般来说会快速返回没有数据,但如果检索条件中存在着多级“OR”检索,则会导致分片需要多次进行数据检索,并且由于索引没有匹配到数据,检索策略会采用Collection scan进行,所以“OR“检索还不如拆分成多次$match执行;
限制导致的坑
众所周知,MongoDB单次检索(指引擎内部的动作)所得的集合大小(含字段内容)不能超过16MB,所以在大批量读取和检索数据的情况下就会出现一些需要特别处理的情况;
单次检索
单词检索指的是MongoDB内部指针完成一次查询动作的检索,我们采用find进行查找的时候,Mongodb会创建一个指针完成一次检索的方式进行检索数据,当采用aggregate的时候,我们可以通过传递指针配置(batchSize),让引擎拆分成一个指针完成多次检索的方式进行检索数据,相当于我们给指针(Cursor)设置一个数据阀值,当取出来的数据达到阀值(条数),MongoDB就会输出一次流来传输数据,用以避免整个查询大小(字节大小)超过16MB;
!!注意 !!
在Mongodb 4.2中,已经取消了
多个指针完成多次检索的功能;
性能不足代码来凑
多次检索
如上所述,引擎内部已经取消了多次指针多次检索功能,所以我们可以利用条件允许的情况下进行代码分片执行并发读取;
例如,
拆日期
日期范围检索,可以拆分为按每周进行检索再进行数据片整合(多次提交查询);
拆范围
in检索可以拆成多个in提交查询;
擒贼先擒王
当能准确预测匹配的结果比较小的时候(集合100w,需要查找的只有3000),甚至可以采先用条件匹配出_id字段,再拿id字段去第二次查出其他字段内容,从而得到一个完整的数据集合,要比直接去查所有字段要快;